01
Observe Synthetic Erosion
Scaling synthetic data improves pronunciation stability first, then progressively suppresses prosodic variability beyond a critical ratio.
ICML 2026 Project Page
Synthetic data can make low-resource spoken language models more stable, but too much of it flattens prosody. SE-Bridge-TTS studies that trade-off and introduces two self-alignment frameworks for expressive Thai and Lao speech.
Overview
The paper frames synthetic speech scaling as a double-edged tool: it supplies phonetic supervision where transcribed speech is scarce, yet it can pull the model toward low-entropy, less expressive prosody.
Scaling synthetic data improves pronunciation stability first, then progressively suppresses prosodic variability beyond a critical ratio.
DGSA constructs identity-consistent preference pairs from structural separation of prosody and timbre, recovering expressivity for Thai.
TDSC uses multi-temperature exploration and filtering to create pseudo-real anchors when authentic Lao references are extremely limited.
Key idea
Synthetic data gives phonetic stability; preference alignment restores the expressive variation that makes speech sound human.
The audio section lets visitors hear benchmark comparisons, zero-shot cloning, erosion across synthetic ratios, and the alignment gains from DGSA and TDSC.
Methods
The project page keeps the method visuals from the original demo and connects them to the paper narrative, so the page works as both an abstract and a guided listening interface.
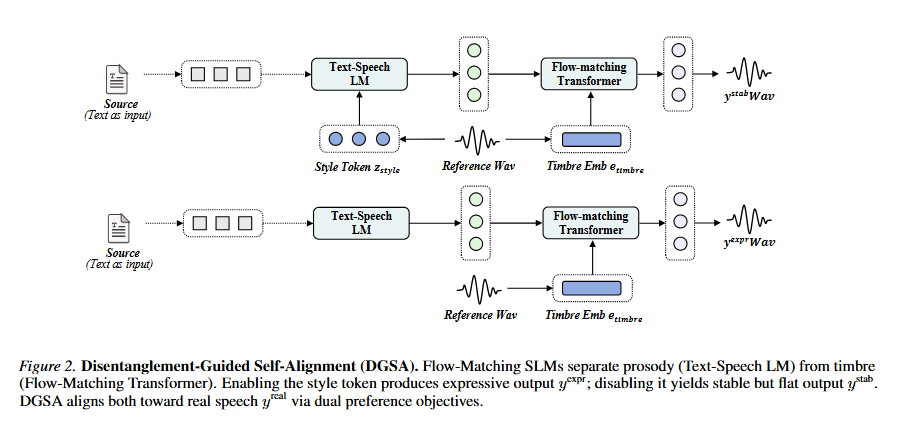
DGSA exploits prosody-timbre separation in flow-matching SLMs to form self-supervised preference pairs that improve expressivity while preserving pronunciation and speaker identity.
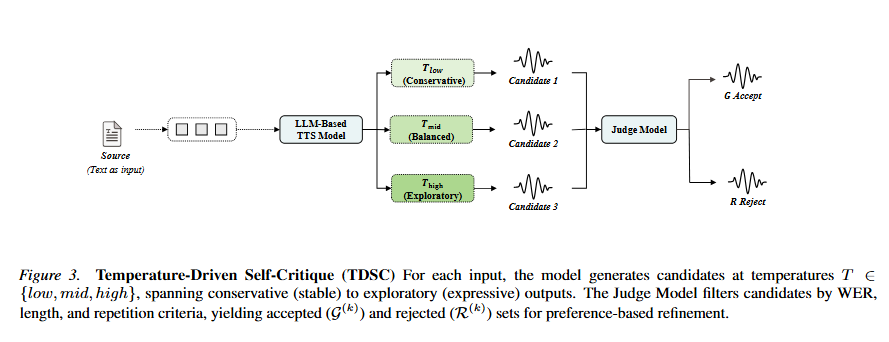
TDSC samples candidates across generation temperatures, filters them automatically, and reuses the accepted outputs as pseudo-real anchors for very low-resource synthesis.
Audio demo
A compact listening set covers benchmark comparisons, zero-shot cloning, synthetic erosion, and the two self-alignment methods.
Results
The numbers below mirror the current project data file and are meant to orient readers before they jump into the listening examples.
Citation
The repository is configured as a project page first. Paper-related code will be added later; Code coming soon.
@inproceedings{geng2026bridging,
title = {Bridging the Stability-Expressivity Gap: Synthetic Data Scaling and Preference Alignment for Low-Resource Spoken Language Models},
author = {Geng, Yizhong and Li, Yanliang and Yang, Jinghan and Jiang, Tianhan and An, Boxun and Li, Ya and Shen, Xiaoyu},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
year = {2026}
}